Types of ML
Hey there! I'm a BSc Data Science graduate from India with expertise in data analysis, machine learning, and statistical modelling. I'm skilled in programming & data visualization and have experience developing predictive models for customer behaviour. I'm highly motivated, detail-oriented, and passionate about using data to solve complex problems. Let's connect and explore opportunities to work together!"
We know already the 4 different types of Machine Learning;
Supervised ML
Unsupervised ML
Semi-Supervised ML
Reinforcement Learning
Dependant vs Independant
When we want to predict something, we use certain pieces of information called "independent variables" to help us. The thing we want to predict is called the "dependent variable" or label data. For example, if we want to predict the price of a flat, we would look at things like the number of rooms, area, floor height, and locality (independent variables) to help us make that prediction. The price of the flat is the thing we want to predict (dependent variable).
Training and Test Data
When we are teaching a machine learning model how to do something, we use "training data" to help it learn. This data is used to adjust the model's settings so that it can make better predictions. After the model has been trained, we use "test data" to see how well it can make predictions. The test data is a way for us to check if the model is accurate and to generate insights that we are interested in.
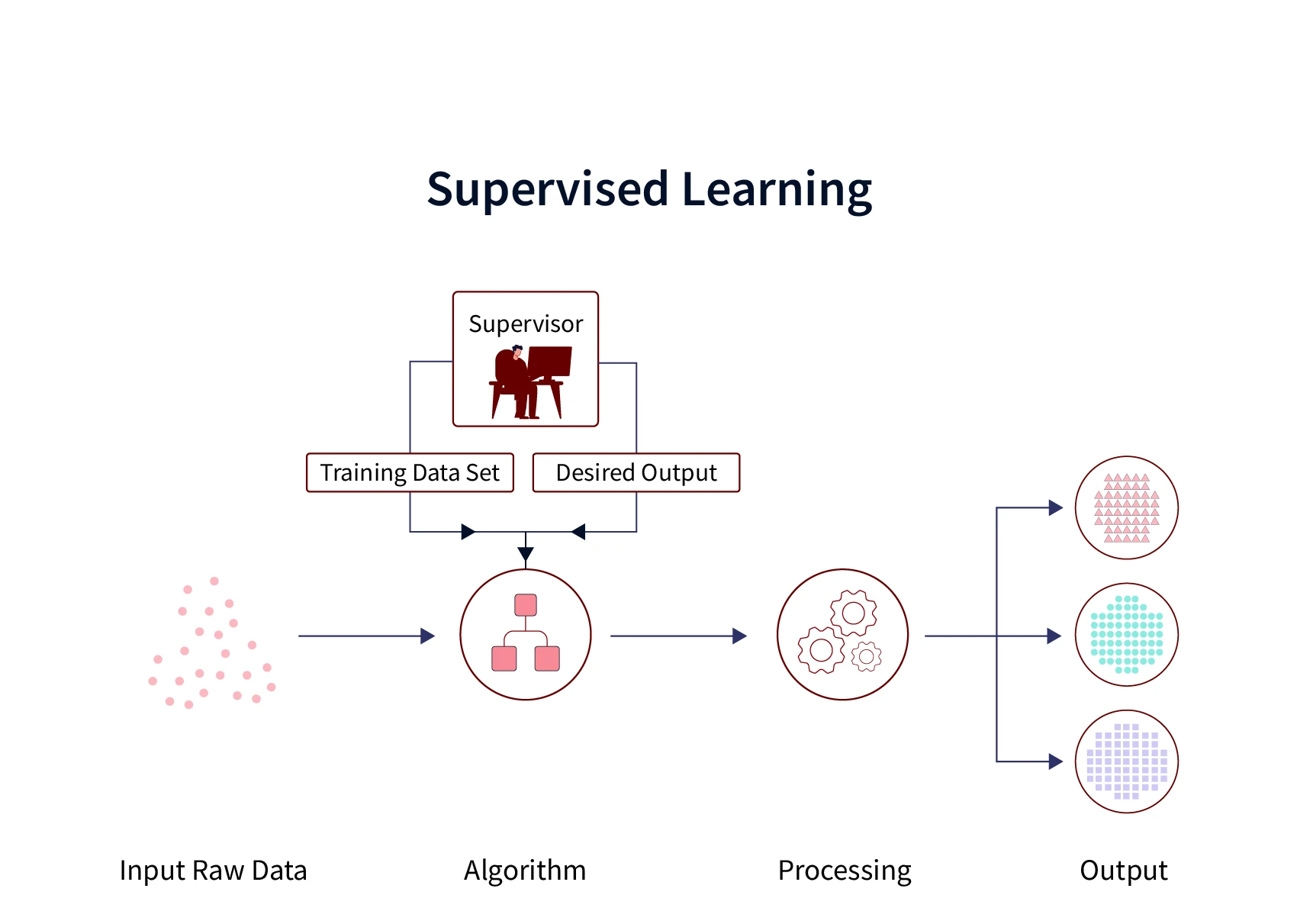
Supervised ML Algorithm
Supervised machine learning algorithms use "labeled data" which means that both independent and dependent variables (also known as labels) are used during training. The algorithm learns how to make predictions based on this data. Later, the algorithm is tested on a separate set of data to see how accurate its predictions are.
There are three types of supervised machine learning algorithms: classification, regression, and forecasting. For example, predicting the price of an item or forecasting the weather are examples of supervised machine learning algorithms.
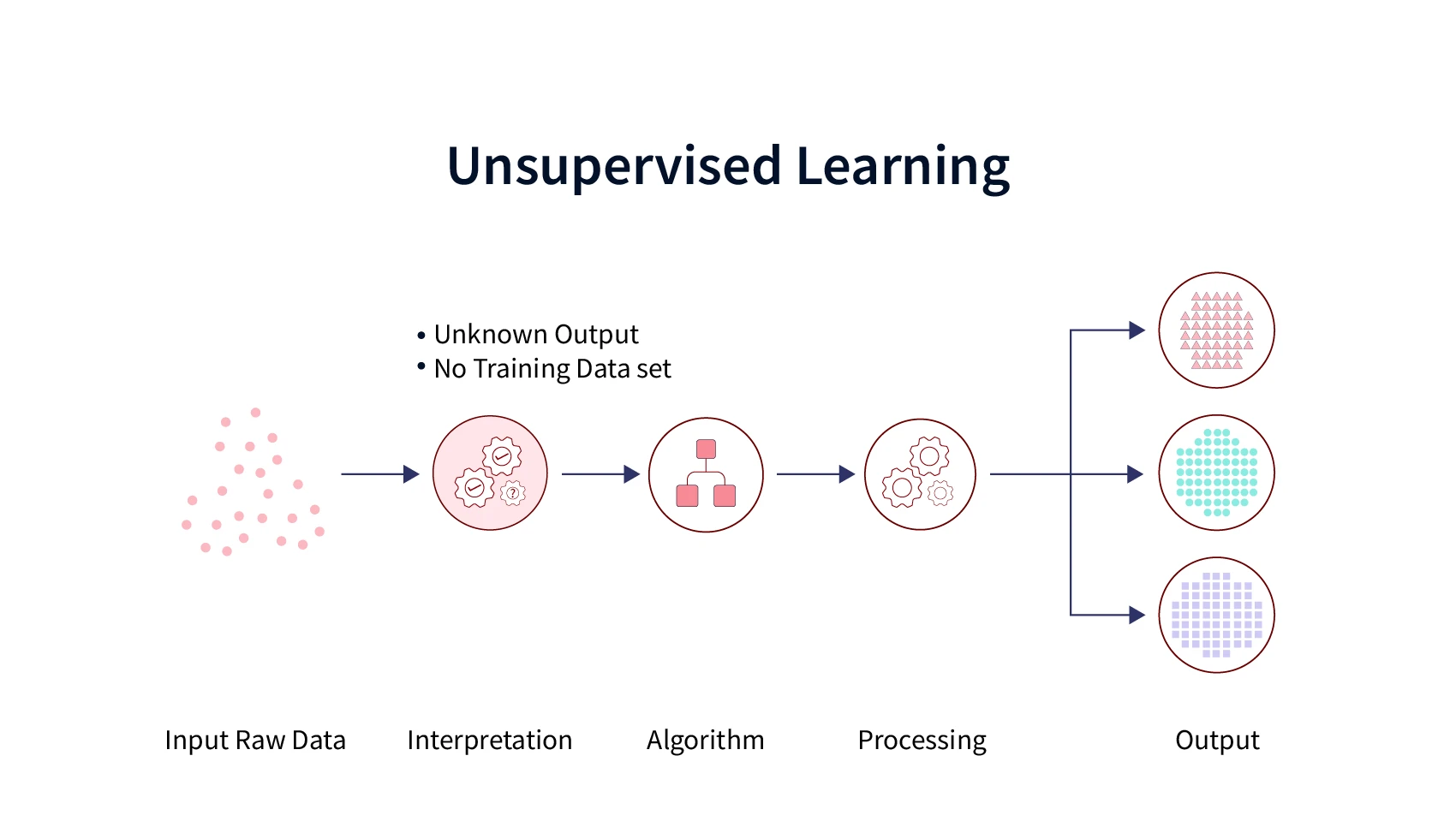
Unsupervised Machine Learning Algorithm
Unsupervised machine learning algorithms don't use labeled data for training, which means there are no dependent variables or labels. Instead, the algorithm groups data based on similarities or differences without any prior knowledge of the data. This process doesn't require any supervision. There are two types of tasks that unsupervised machine learning algorithms can perform: clustering and dimensionality reduction. Clustering is when similar data points are grouped together while dimensionality reduction is when a large set of data is simplified into a smaller, more manageable set without losing important information.
Semi-Supervised ML Algorithm
Semi-supervised machine learning algorithms use both labeled and unlabeled data during training. This is helpful in scenarios where labeled data is scarce or expensive. Semi-supervised techniques strike a balance between using labeled data to make accurate predictions and using the larger pool of unlabeled data to help the algorithm generalize better. These techniques are particularly useful for tasks such as image classification and speech recognition.
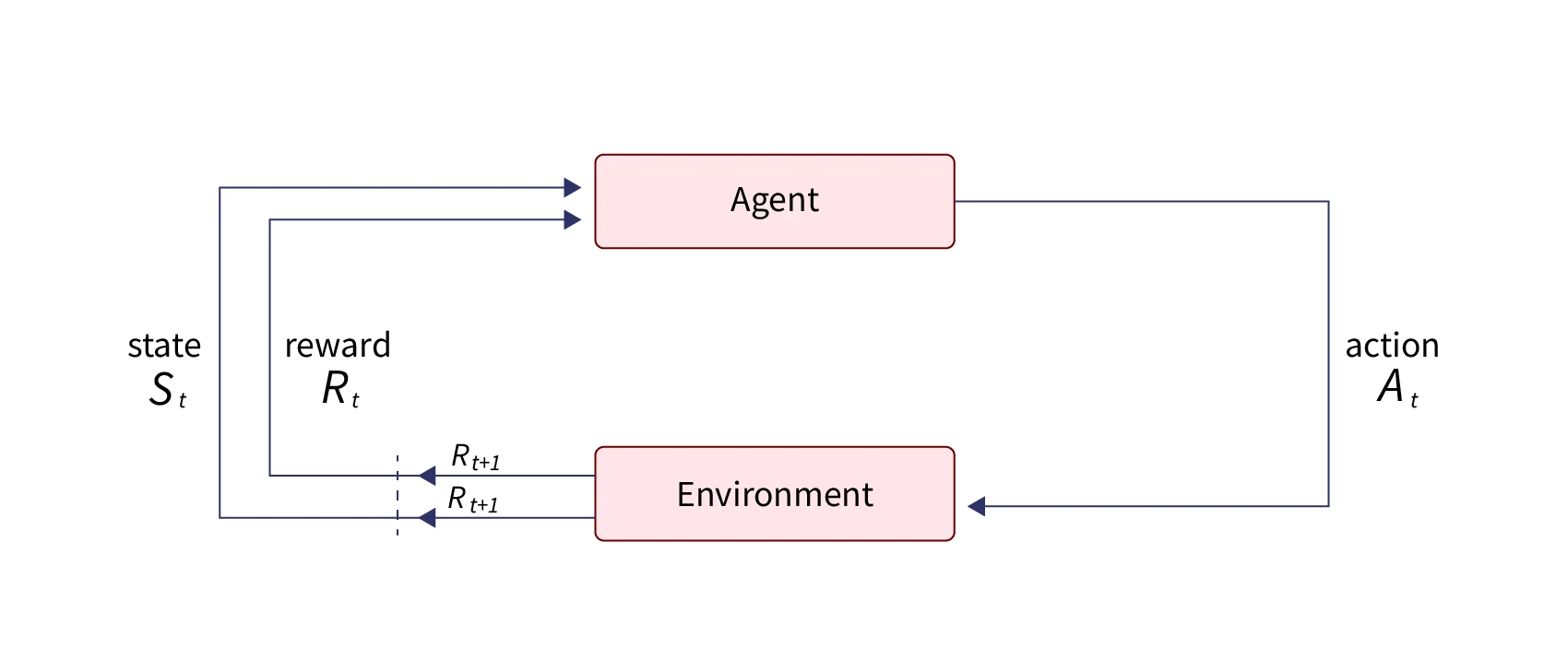
Reinforcement ML Algorithm
In reinforcement learning, an "agent" (a decision maker) interacts with their surroundings to gather information. The agent then explores different options in a trial-and-error manner. The agent's actions are rewarded or punished based on their suitability, creating a feedback system. This type of learning is particularly useful for robotics applications where the agent needs to navigate its surroundings and make decisions based on the environment.
That's the end of the article Readers!
Will be explaining more in the following blogs!
"Any sufficiently advanced technology is indistinguishable from magic." - Arthur C. Clarke.
Keep your curiosity alive and do follow me for more such Articles! 😃